지난번 글에 이어 이번에는 공개된 소스를 활용하여 TTS를 파이썬에서 구현해 보려 한다.
개인적으로 직접 돌려보고 문제를 파악하는 방식의 공부를 선호한다.
그래서 일단 tts 한국어 관련 github를 찾아보았고
https://github.com/hccho2/Tacotron2-Wavenet-Korean-TTS
GitHub - hccho2/Tacotron2-Wavenet-Korean-TTS: Korean TTS, Tacotron2, Wavenet
Korean TTS, Tacotron2, Wavenet. Contribute to hccho2/Tacotron2-Wavenet-Korean-TTS development by creating an account on GitHub.
github.com
해당 소스를 사용하기로 했다.
문제점
tensorflow dependency
2년 전 소스인 듯한데 tensorflow 예전 버전이랑 윈도 10이랑 cuda랑 dependency 있는 듯하다.
(파이썬 버전도 걸려있는 것 같은데 파이썬 3.6 버전을 쓰니 그 부분은 해결했다.)
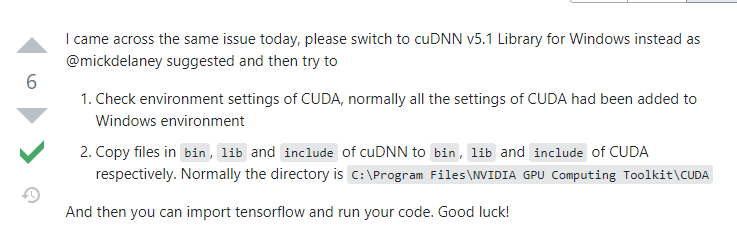
구글링 하다보니 cuda까지 건드려야 하는 거 같다. (여기서 생각보다 시간을 많이 소모했다)
cuda는 건드리기 싫었고.. tensorflow는 경험이 없다 보니 또 다른 이슈가 생기면 대처하는 시간이 상당할 것 같았다.
결국 pytorch 기반 소스를 찾기로 했다.
NVIDIA github에 pytorch 기반 tacotron2가 있었고 pytorch hub에 있는 모델도 사용 가능했다.
한국어 모델은 아닌 것 같지만 파이토치 기반에 데모도 코랩으로 돌려볼 수 있었다.
https://pytorch.org/hub/nvidia_deeplearningexamples_tacotron2/
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
코랩으로 데모를 바로 돌릴수 있고 오디오 파일로 저장도 가능하다. 영어 텍스트의 경우 결과가 상상했던 것 이상이었다.
샘플 텍스트(audio.mp3)
"Hello world, I missed you so much."
많이 부자연스럽지 않을까? 생각했지만 진짜 사람이 말하는 것 같았다. 어색하고 딱딱한 느낌이 아니었다.
한국어는 어떻게 나올지 궁금해서 한국어도 넣어보았다.
샘플 텍스트(audio_ko.mp3)
"동해물과 백두산이 마르고 닳도록"
조금 무섭긴 한데.. 그래도 한국어도 읽기는 한다. 아마 영어가 아닌 언어는 어떤 글자가 어떻게 읽히는지 정도만 학습하지 않았을까 예상해본다. 이 모델에 전이 학습하면 좀 더 수월하지 않을까 하는 생각이 든다.
이후에 학습까지 돌려보려 하니

도커가 필요하다. 도커 없이 로컬 운영체제/환경에서 바로 시도해 보았지만 리눅스 커맨드 때문에 실행 안 되는 부분이 많았다.
(괜히 윈도우에서 해보려고 고집부리다가 시간만 쓰고 해결은 못했다.)
그래서 nvidia docker부터 설치를 해야겠다고 생각했지만
윈도우에서 도커 설치가 바로 되는 게 아니었다.
그래도 설치 가이드 글이 많아 큰 도움이 되었다.
우여곡절 끝에 설치는 끝마쳤고 다음번에 직접 돌려볼 수 있을 것 같다.
윈도우에서 도커 설치
https://seonghyeon-drew.tistory.com/75
Windows에서 WSL2를 이용해서 Docker 설치하기
일반적으로, 윈도우는 개발 환경을 갖추기 까다로운 운영체제로 알려져 있다. 그래서 대부분의 개발자들은 리눅스 환경을 더 선호하고 나 또한 그렇다. 한 1년인가 2년쯤전에 마이크로소프트에
seonghyeon-drew.tistory.com
한국어 음성 데이터셋
https://www.kaggle.com/bryanpark/korean-single-speaker-speech-dataset
Korean Single Speaker Speech Dataset
KSS Dataset: Korean Single Speaker Speech Dataset
www.kaggle.com
https://aihub.or.kr/open_data/21292
카이스트 오디오북 데이터셋 | AI 허브
[주관기관 : 한국과학기술원 (KAIST 인공지능연구소)] 책임자명 : 이수영 대표 이메일 : sy-lee@kaist.ac.kr 실무자 : 조성재 실무자 이메일 : sungjae.cho.1118@gmail.com 담당업무: 음성합성 목적으로 오디오북
aihub.or.kr